Ars Electronica sees itself as a platform for a European data humanism that is to take an alternative path beyond the data capitalism of the IT monopolists and the data totalitarianism of authoritarian regimes. A strategy needs to be developed that allows the potential of AI applications to be exploited to the full while guaranteeing the right for privacy protection. There are no universally valid answers or the “golden road”. The Ars Electronica Center opens up possible approaches to a necessary broad discussion on this subject, for example in the “Understanding AI” exhibition.
Equipped with the necessary background knowledge, technologies are a useful tool for making people’s jobs easier, such as those who are currently on the front line in the fight against the devastating effects of a pandemic. With a series of several blog posts we want to look at which AI-supported methods are used today in the fight against the coronavirus, which could be used in the future, which opportunities and which problems arise.
Mapping and Forecasting
In the first part of our series, we look at the mapping and, consequently, the predictability of pandemics using Big Data. One name that keeps coming up in connection with early warning of the Corona virus outbreak is that of the Canadian health monitoring company BlueDot. According to their own statements and those of several media, they had already sent a report to their customers on December 31, 2019, warning of the Corona virus outbreak in China and the rest of the world. WHO informed the public on 9 January.
BlueDot works with huge amounts of data,with Big Data. The company uses Natural Language Processing (NLP) and Machine Learning to filter data from hundreds of thousands of sources – including statements from official health organizations, digital media data, global airline ticket data, animal health reports and demographic population data. This allows a huge amount of data to be processed very quickly. Experts such as epidemiologists, doctors and scientists then evaluate the results, check the data and produce reports that are then sent to customers – mostly hospitals or government agencies, but no private individuals.
“We do not use Artificial Intelligence to replace human intelligence, but we basically use it to find the needles in the haystack and present them to our Team.”
BlueDot aims not only to identify the threat of infectious diseases as early as possible, but also to understand how diseases could spread to different parts of the world and then to determine the possible consequences of their spread. In the case of COVID-19, BlueDot was able not only to send out a warning, but also to correctly identify the cities that are highly connected to Wuhan, for example by using global air ticket data to predict where the infected could potentially travel to. The international destinations that BlueDot assumed would have the most travelers from Wuhan were Bangkok, Hong Kong, Tokyo, Taipei, Phuket, Seoul and Singapore. Finally, eleven of the top-listed cities were also the first places affected by COVID-19 cases. For WHO, which is dependent on official statistics from Chinese authorities, which were difficult to access, especially at the beginning, it was not possible to make forecasts earlier because of the data available. For BlueDot, however, it was.
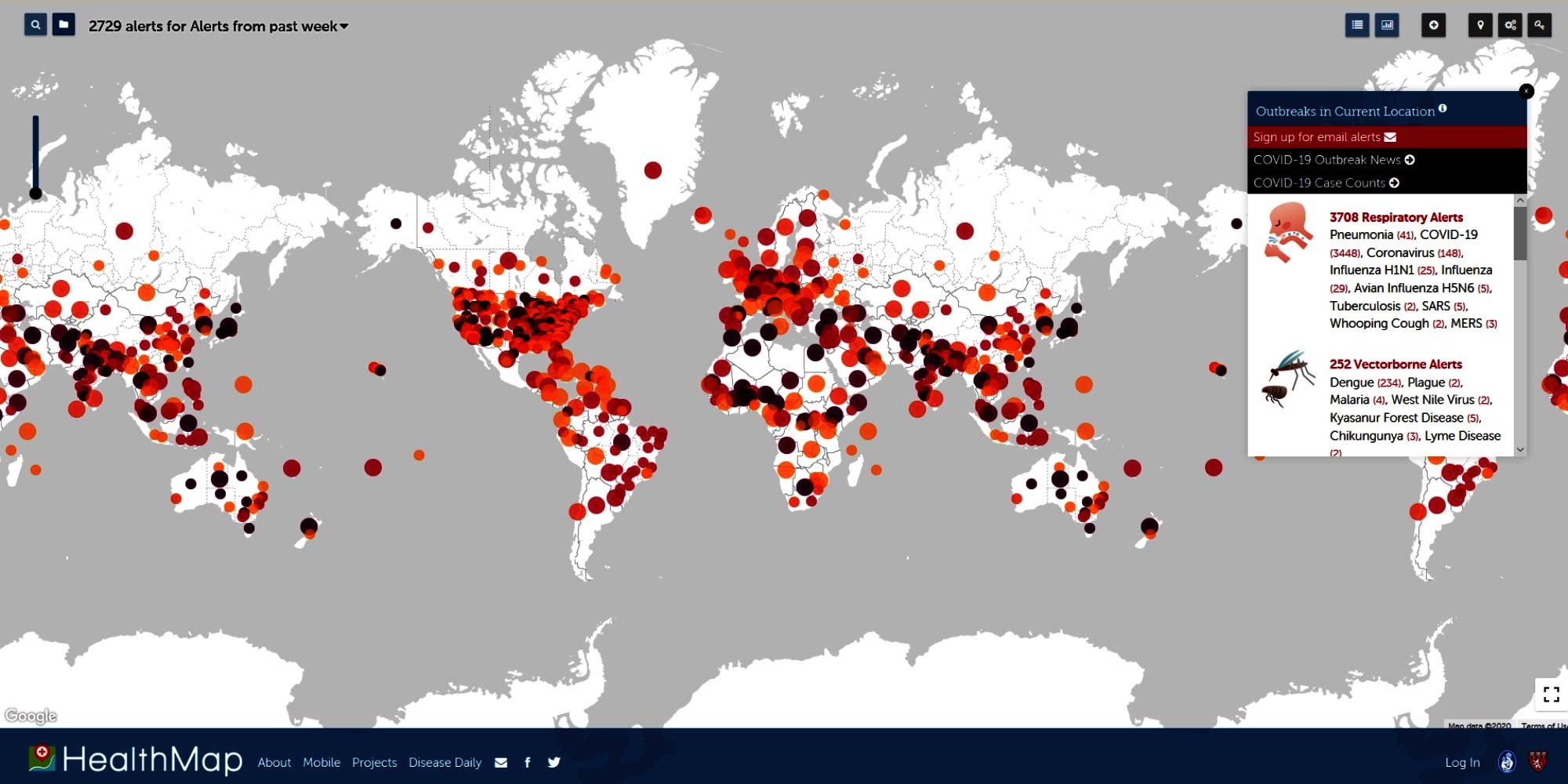
Another company or platform that uses Big Data to map – in this case literally – health forecasts is Health Map. In contrast to BlueDot, which does not use data from social networks, Health Map, in which the Harvard Medical School and the Boston Children’s Hospital are involved, is an important data basis. On their website, however, they state: “All data we use to produce this map comes exclusively from publicly available sources such as government reports or news media.”
John Brownstein, Chief Innovation Officer at Harvard Medical School and an expert in extracting information from social media for health trends, is part of an international team that uses machine learning to scan social media posts, news reports, data from official health channels and information from doctors for warning signs that the virus is emerging in countries outside China.
Nevertheless, the use of AI in healthcare and the spread of health warnings for the Corona virus is not that unproblematic, says Brownstein. The biggest challenge is to create a convincing and reliable global data set on the virus and its spread, based on several national data sets with possibly different metrics.
“There are different structures and taxonomies, the way people relate to the disease, different languages, the cultural context, terms people use in connection with the disease that could be used for other kinds of things. So a lot of filtering is required, and it takes a considerable amount of system training to get to the point where these tools become valuable.“
Further Approaches and a Failed Attempt
In addition to these two major approaches to using Big Data for mapping and forecasting health-related issues such as pandemics, the following approaches should also be mentioned:
WeBank China, also a start-up and simultaneously a Chinese online bank, uses artificial intelligence to predict the future recovery of the Chinese economy from COVID-19.
Medical Home Network, a non-profit organization for innovation in healthcare in the Chicago area, uses artificial intelligence to identify individuals who are more vulnerable to serious complications from COVID-19. For people facing challenges such as homelessness or lack of access to transportation, it can be difficult to take action to protect against or treat COVID-19. Medical Home Network relies on ClosedLoop.ai‘s COVID-19 Vulnerability Index (CV19 Index) to prioritize care for patients most at risk from the virus.
“We want to identify the so-called ‘socially isolated’ people or people without close friends or family, so that our care teams can proactively educate about COVID-19 and offer support to people.”
Finally, an example from Israel, where the authorities have not yet carried out extensive COVID-19 testing. Scientists have sought and found an alternative: They have asked the population to answer short online surveys every day, giving details of their health status as well as where they live. The results are analysed using machine learning algorithms, which provide the scientists and the health ministry with information about the spread of the virus.
Finally, a failed attempt to use Big Data to identify health trends: Google Flu Trends was a web-based service from Google that was launched in 2008. It provided estimates of influenza activity for more than 25 countries. By aggregating Google search queries, it attempted to make accurate predictions about influenza activity. Google Flu Trends stopped publishing the current estimates on August 9, 2015. Historical estimates are still available, and current data are only provided for designated research purposes. One problem with the system was accuracy, as there was often a massive overestimation of disease. Privacy issues were another reason why Google Flu Trends was discontinued.
In the second part of our series, we look at the role of AI in the treatment and diagnosis of COVID-19 disease and we show you examples of how robots are already being used in the event of a pandemic.