Die Ars Electronica sieht sich als Plattform eines europäischen Datenhumanismus, der einen alternativen Weg, abseits des Datenkapitalismus der IT-Monopolisten und des Datentotalitarismus autoritärer Regime, einschlagen soll. Es gilt eine Strategie zu entwickeln, die erlaubt, das Potenzial von KI-Anwendungen auszuschöpfen und gleichzeitig das Recht auf den Schutz unserer Privatsphäre garantiert. Allgemeingültige Antworten oder den „Goldenen Weg“ gibt es nicht, mögliche Ansätze einer notwendigen breiten Diskussion dazu eröffnet das Ars Electronica Center, etwa in der Ausstellung „Understanding AI“.
Mit dem nötigen Hintergrundwissen ausgestattet, sind die Technologien ein sinnvolles Instrument, um Menschen ihre Arbeit zu erleichtern, wie zum Beispiel jenen, die gerade an vorderster Front gegen die verheerenden Auswirkungen einer Pandemie kämpfen. Mit einer Serie mehrerer Blogbeiträge wollen wir uns ansehen, welche KI-unterstützten Methoden heute in der Bekämpfung des Coronavirus zum Einsatz kommen, welche zukünftig angewendet werden könnten, welche Chancen und welche Problematiken sich dabei ergeben.
Mapping und Vorhersage
Im ersten Teil unserer Serie widmen wir uns dem Mapping und infolgedessen der Vorhersagbarkeit von Pandemien mithilfe von Big Data. Ein Name, der immer wieder in Zusammenhang mit der frühzeitigen Warnung vor dem Ausbruch des Coronavirus auftaucht, ist der des kanadischen Health-Monitoring Unternehmens BlueDot. Nach eigenen Angaben und Angaben mehrerer Medien, hatten sie an ihre KundInnen bereits am 31. Dezember 2019 einen Bericht verschickt, in dem sie vor dem Ausbruch des Coronavirus in China sowie im Rest der Welt gewarnt hatten. Die WHO informierte die Öffentlichkeit am 9. Jänner.
BlueDot arbeitet mit riesigen Datenmengen, mit Big Data. Das Unternehmen nutzt Natural Language Processing (NLP), die Verarbeitung natürlicher Sprachen, sowie Machine Learning, maschinelles Lernen, also die Generierung von Wissen aus Erfahrung durch ein System, um Daten aus Hunderttausenden von Quellen herauszufiltern – darunter Aussagen offizieller Gesundheitsorganisationen, Daten digitaler Medien, globale Flugticketdaten, Berichte über die Tiergesundheit und demographische Bevölkerungsdaten. So kann eine riesige Datenmenge sehr schnell verarbeitet werden. ExpertInnen wie EpidemologInnen, ÄrztInnen und WissenschaftlerInnen bewerten dann die Ergebnisse, sie führen eine Prüfung der Daten durch und erstellen Berichte, die dann an die KundInnen – großteils Spitäler oder Behörden, jedenfalls aber keine Privatpersonen – verschickt werden.
„Wir setzen künstliche Intelligenz nicht ein, um die menschliche Intelligenz zu ersetzen, sondern wir verwenden sie im Grunde genommen, um die Nadeln im Heuhaufen zu finden und sie unserem Team zu präsentieren.“
BlueDot will nicht nur die Bedrohung durch Infektionskrankheiten so früh wie möglich erkennen, sondern auch verstehen, wie sich Krankheiten auf verschiedene Teile der Welt ausbreiten könnten, und dann die möglichen Folgen ihrer Ausbreitung ermitteln. Im Fall von COVID-19 konnte BlueDot nicht nur eine Warnung aussenden, sondern auch die Städte, die in hohem Maße mit Wuhan verbunden sind, korrekt identifizieren, indem es beispielsweise globale Flugticketdaten verwendete, um vorauszusehen, wohin die Infizierten potentiell reisen könnten. Die internationalen Ziele, bei denen BlueDot davon ausging, dass sie die meisten Reisenden aus Wuhan haben würden, waren: Bangkok, Hongkong, Tokio, Taipeh, Phuket, Seoul und Singapur. Elf der ganz vorne gelisteten Städte waren schließlich auch die ersten Orte, die von COVID-19-Fällen betroffen waren. Für die WHO, die von den offiziellen Statistiken chinesischer Behörden abhängig ist, die vor allem zu Beginn schwer zugänglich waren, war es aufgrund der Datenlage nicht möglich, früher Prognosen zu treffen. Für BlueDot jedoch schon.
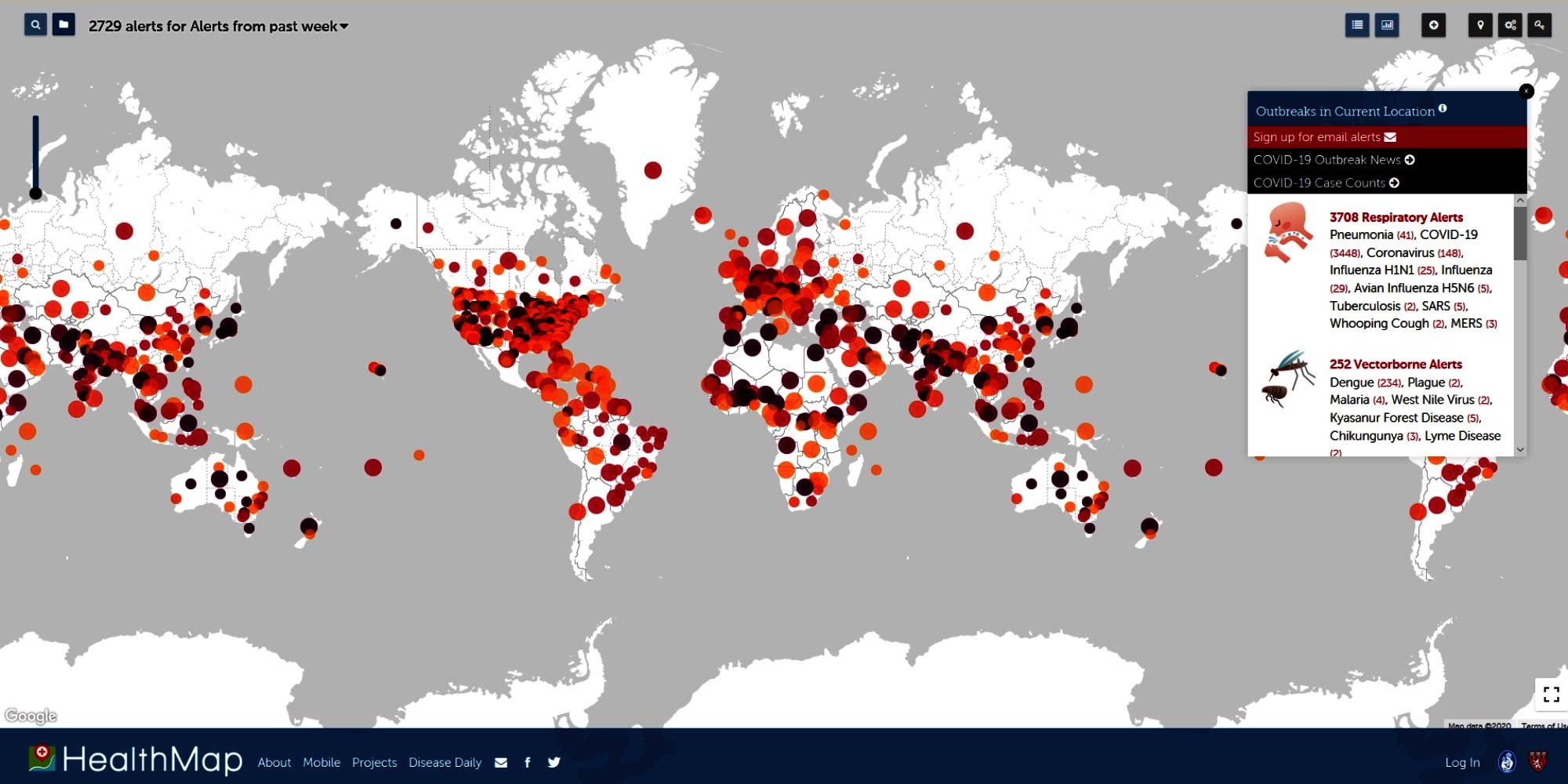
Ein weiteres Unternehmen beziehungsweise eine Plattform, die Big Data zum Mapping – in diesem Fall wörtlich zu verstehen – von Gesundheitsprognosen benutzt, ist Health Map. Im Gegensatz zu BlueDot, die keine Daten aus Sozialen Netzwerken verwenden, stellen genau jene für Health Map, an dem etwa die Harvard Medical School oder das Boston Children’s Hospital beteiligt sind, eine wichtige Datengrundlage dar. Auf ihrer Website halten sie allerdings fest: “Alle Daten, die wir verwenden, um diese Karte zu produzieren, stammen ausschließlich von öffentlich zugänglichen Quellen wie Regierungsberichten oder Nachrichtenmedien.”
John Brownstein, Chief Innovation Officer an der Harvard Medical School und Experte für die Gewinnung von Informationen aus sozialen Medien für Gesundheitstrends, ist Teil eines internationalen Teams, das maschinelles Lernen einsetzt, um Social-Media-Posts, Nachrichtenberichte, Daten aus offiziellen Gesundheitskanälen und Informationen von ÄrztInnen nach Warnzeichen zu durchforsten, die darauf hindeuten, dass das Virus in Ländern außerhalb Chinas auftaucht.
Nichtsdestotrotz ist die Verwendung von KI im Gesundheitswesen und die Verbreitung von Gesundheitswarnungen für das Coronavirus nicht ganz unproblematisch, sagt Brownstein. Die größte Herausforderung ist die Erstellung eines überzeugenden und zuverlässigen globalen Datensatzes über das Virus und seine Verbreitung, der sich auf mehrere nationale Datensätze mit möglicherweise unterschiedlichen Metriken stützt.
„Es gibt verschiedene Strukturen und Taxonomien, die Art und Weise, wie Menschen sich auf die Krankheit beziehen, verschiedene Sprachen, den kulturellen Kontext, Begriffe, die Menschen rund um die Krankheit verwenden, die für andere Arten von Dingen verwendet werden könnten. Es ist also eine Menge an Filterung erforderlich, und es erfordert eine beträchtliche Menge an Systemschulung, um an den Punkt zu gelangen, an dem diese Werkzeuge wertvoll werden.“
Weitere Ansätze und ein gescheiterter Versuch
Neben diesen beiden großen Ansätzen, Big Data zum Mapping und zur Prognose von gesundheitsrelevanten Themen wie etwa Pandemien zu verwenden, seien auch noch folgende Ansätze erwähnt:
WeBank China, ebenfalls ein StartUp und gleichzeitig eine chinesische Onlinebank, benutzt Künstliche Intelligenzen, um die zukünftige Wiederherstellung der chinesischen Wirtschaft von COVID-19 vorherzusagen.
Medical Home Network, eine gemeinnützige Organisation für Innovationen im Gesundheitswesen im Raum Chicago, setzt Künstliche Intelligenz ein, um Personen zu identifizieren, die eine erhöhte Anfälligkeit für schwere Komplikationen durch COVID-19 aufweisen. Für Menschen, die mit Herausforderungen wie Obdachlosigkeit oder mangelndem Zugang zu Transportmitteln konfrontiert sind, kann es schwierig sein, Maßnahmen zum Schutz vor oder zur Behandlung von COVID-19 zu ergreifen. Medical Home Network setzt auf den COVID-19 Vulnerability Index (CV19 Index) von ClosedLoop.ai, um die Betreuung der am stärksten durch das Virus gefährdeten Patienten zu priorisieren.
„Wir wollen die so genannten ’sozial isolierten‘ Menschen oder Menschen ohne nahe stehende FreundInnen oder Familie identifizieren, damit unsere Pflegeteams proaktiv über COVID-19 aufklären und den Menschen Unterstützung anbieten können.“
Zuletzt ein Beispiel aus Israel, wo die Behörden bis jetzt noch keine weitläufigen COVID-19-Test durchführen. WissenschaftlerInnen haben eine Alternative gesucht und gefunden: Sie haben die Bevölkerung gebeten, täglich kurze Onlineumfragen zu beantworten, die Details über den Gesundheitszustand ebenso beinhalten wie den Wohnort. Das Ergebnis wird mittels Machine Learning Algorithmen analysiert, die den WissenschaftlerInnen und dem Gesundheitsminiersterium Auskunft über die Ausbreitung des Virus geben.
Zum Schluss noch ein gescheiterter Versuch, Big Data zur Identifizierung von Gesundheitstrends zu verwenden: Google Flu Trends war ein webbasierter Service von Google, der bereits 2008 gestartet wurde. Er lieferte Schätzungen über die Influenza-Aktivität für mehr als 25 Länder. Durch die Aggregation von Google-Suchanfragen versuchte man, genaue Vorhersagen über die Grippeaktivität zu treffen. Google Flu Trends hat die Veröffentlichung der aktuellen Schätzungen am 9. August 2015 eingestellt. Historische Schätzungen stehen weiterhin zur Verfügung, aktuelle Daten werden nur für ausgewiesene Forschungszwecke angeboten. Ein Problem des Systems war die Genauigkeit, da es oftmals zu einer massiven Überschätzung von Krankheiten kam. Datenschutzprobleme waren ein weiterer Grund, warum Google Flu Trends eingestellt wurde.
Im zweiten Teil unserer Serie widmen wir uns der Rolle von KI in Bezug auf die Behandlung und die Diagnose bei einer COVID-19 Erkrankung und wir zeigen euch Beispiele, wie auch Roboter im Pandemie-Fall bereits zum Einsatz kommen.