
Einerseits scheint man gemeinhin zu glauben, dass Staaten und große Unternehmen ohnehin alles über uns wissen. Andererseits flicken sie ihr Wissen über uns aus einem sehr selektiven und chaotischen Datensatz zusammen – aus einem Teil unserer digitalen Online-Spuren. Heutzutage können Metadaten in einem noch nie dagewesenen Maßstab gesammelt und analysiert werden. Gleichzeitig kann diese Tatsache leicht darüber hinwegtäuschen, dass eine Menge dieses – zweifellos sehr machtvollen – Wissens, das Institutionen über uns haben, höchst spekulativer Natur ist.
Algorithmen, die beim maschinellen Lernen zum Einsatz kommen, versuchen, allgemein Gültiges aus Beobachtungen abzuleiten. Die konkreten Ergebnisse hängen jedoch sehr stark von der Qualität der Daten („garbage in, garbage out“), vom Parameter-Tuning und der Optimierung verschiedener konkurrierender Ziele ab (wie Trefferquote und Genauigkeit). Aufgrund ihrer Zweckorientierung (z. B. die Platzierung von Anzeigen oder das Aufspüren von Terroristen) implizieren existierende Klassifizierungssysteme außerdem immer auch versteckte Vorurteile, Annahmen und Belohnungssysteme, die die von der Maschine wahrgenommene „Wirklichkeit“ färben, und zwar ab dem Moment der Datenerfassung. Moritz Stefaner, Mark Shephard und Julian Oliver erklären anhand ihres Projekts „False Positive“ das Design und die Parameter zur Erstellung eines auf Daten basierendes User-Profils.
Wie funktioniert das Profiling Ihres fiktiven Unternehmens Candygram?
Moritz Stefaner: Das Design der Corporate Identity von Candygram und die Präsentationen, die wir den Usern zeigen (also ihre Datenprofile) spiegeln diese oben erwähnten Spannungen wider. Die Präsentation beginnt mit sehr einfachen, unverfänglichen Fakten (wie Name, Beruf und Wohnort einer Person). Basierend auf assoziativen Kriterien zeigt sie dann im nächsten Schritt entsprechendes Bildmaterial und schließlich Wortkombinationen. So wird ein semantischer Kontext rund um ein Personenprofil gebildet und ein höchst spekulatives Persönlichkeitsprofil abgesteckt. In diesem Profil wird der Person eine numerische Bewertung zugeteilt, die den im „Big Five“- oder Fünf-Faktoren-Modell beschriebenen Persönlichkeitsmerkmalen entspricht.
Dadurch wird genau jene kognitive Dissonanz getriggert, die uns interessiert. Dies reicht von „Wie kann es sein, dass sie alles über mich wissen?“ oder „Glauben die wirklich, dass sie mich anhand so weniger Daten beurteilen können?“ bis hin zu „Das ist schlicht und ergreifend falsch, ich fühle mich dadurch falsch dargestellt“. Dadurch, dass wir mit fundierter Information beginnen und dann immer spekulativer werden, wird der Prozess der Extrapolierung aufgrund von unvollständigen Informationen greifbar und erhält Relevanz für den Einzelnen.

Mark Shepard im Gespräch und auf dem Schirm. Credit: Mark Shephard
Was können Daten aus Mobilfunknetzwerken über uns verraten? Und wo liegen die Grenzen dieser Art von Profiling?
Mark Shephard: Ganz prinzipiell produzieren unsere Mobiltelefone digitale Spuren, die die Orte, die wir besuchen, dokumentieren. Das ist der sogenannte Standortverlauf. Anhand dieser Daten ist es möglich zu erkennen, wie oft wir wo waren und wohin wir wahrscheinlich als nächstes gehen werden. Es ist trivial, diese Standorte mit konkreten Örtlichkeiten in Verbindung zu bringen und Vermutung darüber anzustellen, was wir dort tun. Wenn die Standortverläufe einer großen Menge von Mobilfunkkunden aggregiert werden, ist es möglich abzuleiten, mit wem wir wie oft wo zusammen waren usw. Diese räumlichen Beziehungen basieren jedoch auf den Daten von Handys, die eine SIM-Karte enthalten, die nicht unbedingt einem spezifischen Individuum zugeordnet werden kann, denn in manchen Gegenden der Welt ist es üblich, ein Handy mit vielen anderen zu teilen.
In machen Situationen sind wir auch ohne Handy unterwegs. Dann ist es nicht mehr möglich, eine eindeutige Beziehung zwischen einem Standortverlauf und einem spezifischen Individuum herzustellen. Anhand anderer Informationen, die unsere Mobiltelefone über uns verraten – wie z. B. Metadaten, die zeigen, mit wem wir telefonieren oder wem wir Textnachrichten schicken, die Dauer von Anrufen etc. – kann der Graph des sozialen Netzwerks einer Person erstellt werden. Diese sozialen Beziehungen können sehr aussagekräftig sein. Zum Beispiel zeigte eine Untersuchung von zwei Studenten am MIT, wie man die sexuelle Orientierung einer Person ziemlich genau aus den Freundschaftsbeziehungen, die sie auf Facebook unterhält, ablesen kann.

Das Publikum der Post City beim Ars Electronica Festival 2015 riskiert einen Blick was ihr Online-Verhalten über sie verrät. Credit: Mark Shephard
Werden dadurch tatsächlich Daten preisgegeben, ohne dass wir uns dessen bewusst wären?
Julian Oliver: Das ist ziemlich sicher der Fall, auch wenn es inzwischen viele Initiativen gibt, die das Bewusstsein der User dafür, was diese Daten über uns verraten können, stärken wollen. Die Dokumente, die Edward Snowden öffentlich gemacht hat, sind das bekannteste Beispiel dafür. Weniger bekannt ist jedoch, dass diskrete Datenpunkte, die an und für sich banal zu sein scheinen, algorithmisch bearbeitet werden können und dann Erkenntnisse ermöglichen, die aus den Datenpunkt allein nicht abgelesen werden können.
Vor allem seit Snowden die Aktivitäten der NSA aufgedeckt hat, sollte die Öffentlichkeit eigentlich wissen, dass wir bei unseren Internet-Aktivitäten bespitzelt werden. Wie erklärt es sich, dass wir eine solche Preisgabe unserer Daten zu akzeptieren scheinen? Leben wir einer narzisstisch geprägten Zeit? Oder ist es Fatalismus, der die Leute so sorglos sein lässt? Welche Erfahrungen hast du in den Gesprächen mit Personen gemacht, die an deinem Projekt teilgenommen haben?
Mark Shephard: Meines Erachtens gibt es dafür mindestens zwei Erklärungen. Erstens sind wir immer mehr bereit, gewisse Informationen über unsere Person gegen einen freien Zugang zu Online-Diensten einzutauschen. Wenn wir unsere Email-Adresse bekannt geben, um am Flughafen online gehen zu können, dann machen wir genau das. Das ist weniger eine Frage von Narzissmus, sondern eher eine Frage der Bequemlichkeit. Und dann gibt es ein Argument, das wir alle schon gehört haben: „Ich habe nichts zu verheimlichen, also brauche ich mir keine Sorgen zu machen.“ Leider berücksichtigt diese Haltung nicht die Tatsache, dass personenbezogene Informationen oft jahrelang gespeichert werden. So mag es stimmen, dass man im Moment nichts zu verbergen hat, aber die Dinge können sich ändern: Wenn es neue Gesetze gibt oder sich neue kulturelle Perspektiven durchsetzen, kann Information, die im Moment relativ harmlos erscheint, in Zukunft ganz andere Implikationen haben.
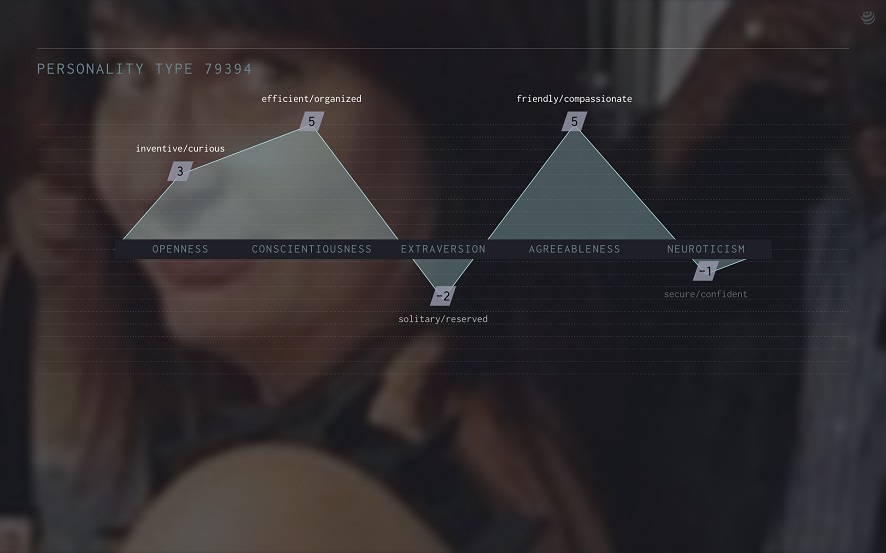
Ein Persönlichkeitsprofil als Screenshot. Credit: Mark Shephard
Wenn die TeilnehmerInnen an Ihrem Projekt wissen, wie ihre Daten im Netz gesammelt werden, verändert sich dann ihr Verhalten?
Moritz Stefaner: Ja, es verändert sich. Die meisten Menschen wollen sehr wohl wissen, wie sie mehr Kontrolle über jene Informationen bekommen können, die im Netz über sie verfügbar sind. Nur wenigen TeilnehmerInnen war dieser Aspekt ganz egal. Am Ende der Beratung bieten wir den TeilnehmerInnen eine Broschüre an, die eine Reihe von Online-Ressourcen auflistet, wo sie sich über Best Practice in Sachen digitaler Sicherheit im Netz informieren können. Wir haben auch Workshops organisiert, bei denen wir Tools und Techniken für sicheres Web-Browsing, E-Mail, Chat etc. vorstellen.
Weitere Projekte, die im Rahmen es EU-Projekts „Connecting Cities“ entstanden sind, finden Sie auf www.connectingcities.net.